
How to Extract Structured Data from PDFs Using LlamaIndex and n8n
If you've ever tried to pull specific information from a PDF: company names, funding amounts, contact details, you know it's tedious work. Traditional OCR gives you text, sure, but it doesn't understand what that text means or how it should be organised.
LlamaIndex's extraction tools change that. Instead of dumping raw text at you, they let you define exactly what data you want and return it in a clean, structured format you can actually use. So when you wire this into an n8n workflow, you can automate the entire process. No copy-pasting, no manual data entry.
In this tutorial, we'll walk through building an n8n workflow that uses LlamaIndex Cloud to extract structured data from pitch decks. You'll learn how to set up the API calls, handle asynchronous jobs, and get back JSON that's ready to feed into your CRM, database, or wherever else you need it.
What Problem Does This Solve?
Let's say you're a VC analyst reviewing dozens of pitch decks every week. Each deck has the same basic info: company name, founders, funding ask, market size, but it's scattered across slides in different formats.
Manually extracting this into a spreadsheet takes hours. Traditional OCR tools give you all the text, but you still have to hunt through paragraphs to find what you need.
LlamaIndex Extraction solves this by letting you define a schema: basically a template that says "I want company name, funding amount, and team size", and it pulls exactly those fields from the document. The result is structured JSON you can immediately use in automation workflows.
This isn't just for pitch decks. You can use the same approach for invoices, contracts, forms, research papers, any document where you need specific data points extracted reliably.
What You'll Need
Before you start building, make sure you have:
- An n8n instance (cloud or self-hosted)
- A LlamaIndex Cloud account with an API key (sign up here)
- A custom extraction agent set up in LlamaIndex Cloud (we'll cover what this is in a moment)
- A sample PDF to test with (a pitch deck works great)
If you're new to LlamaIndex Cloud, you'll want to create an extraction agent first. This is where you define your schema: the fields you want extracted. You can do this manually or let LlamaIndex generate a schema by uploading example documents and describing what you need.
It’s honestly as simple as:
1. Go to Extract, in the left-hand menu
2. Tap on the playground sign and select “Manage Agents”
3. Create a new agent by pressing the button in the top right and give it a name. We called our granite-agent.
4. Click on your agent’s name
5. Select Auto-Generate (this is the fastest way to get setup)
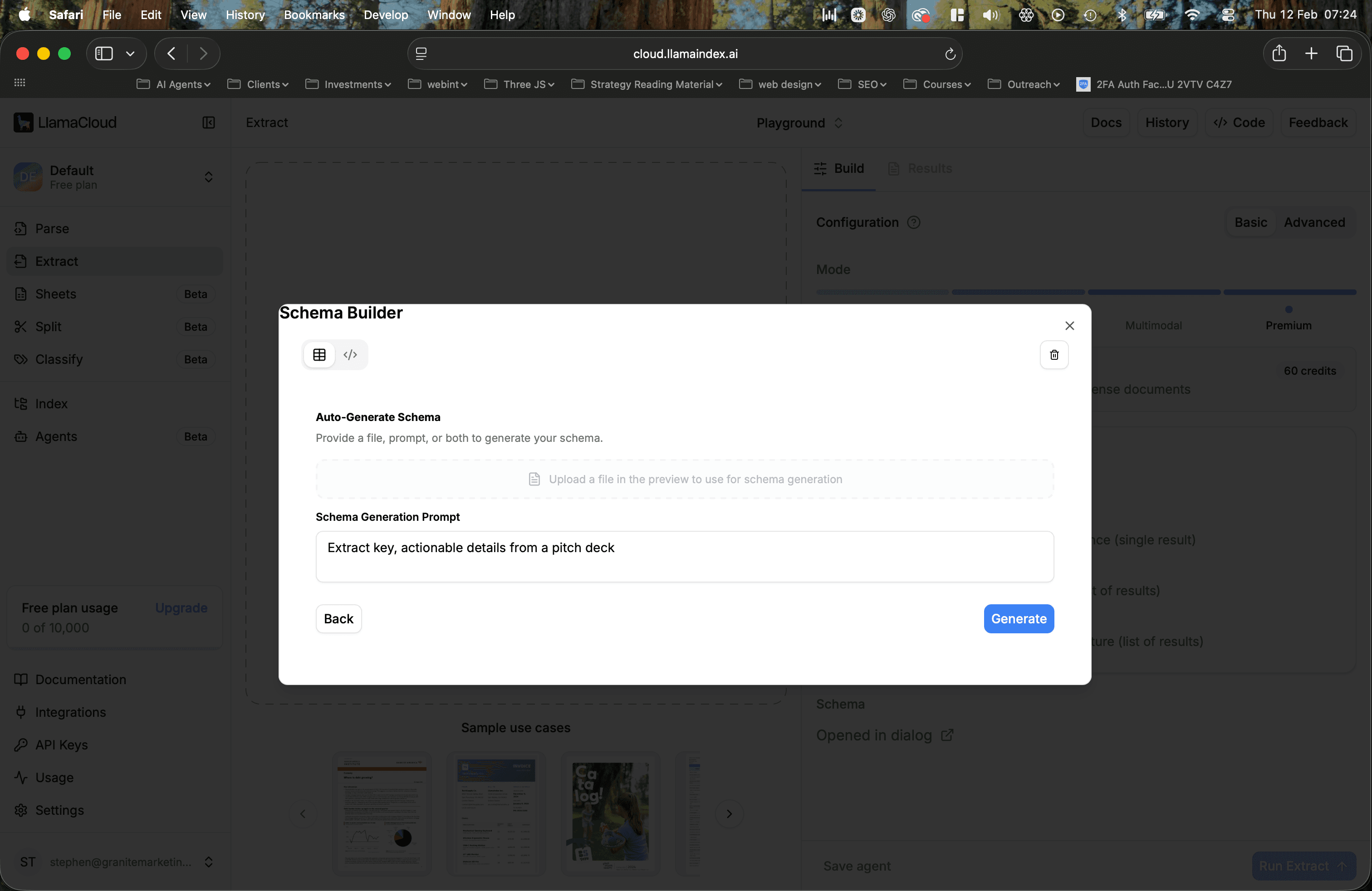
6. Write a simple prompt or upload a file to get suggestions
7. Confirm your field names
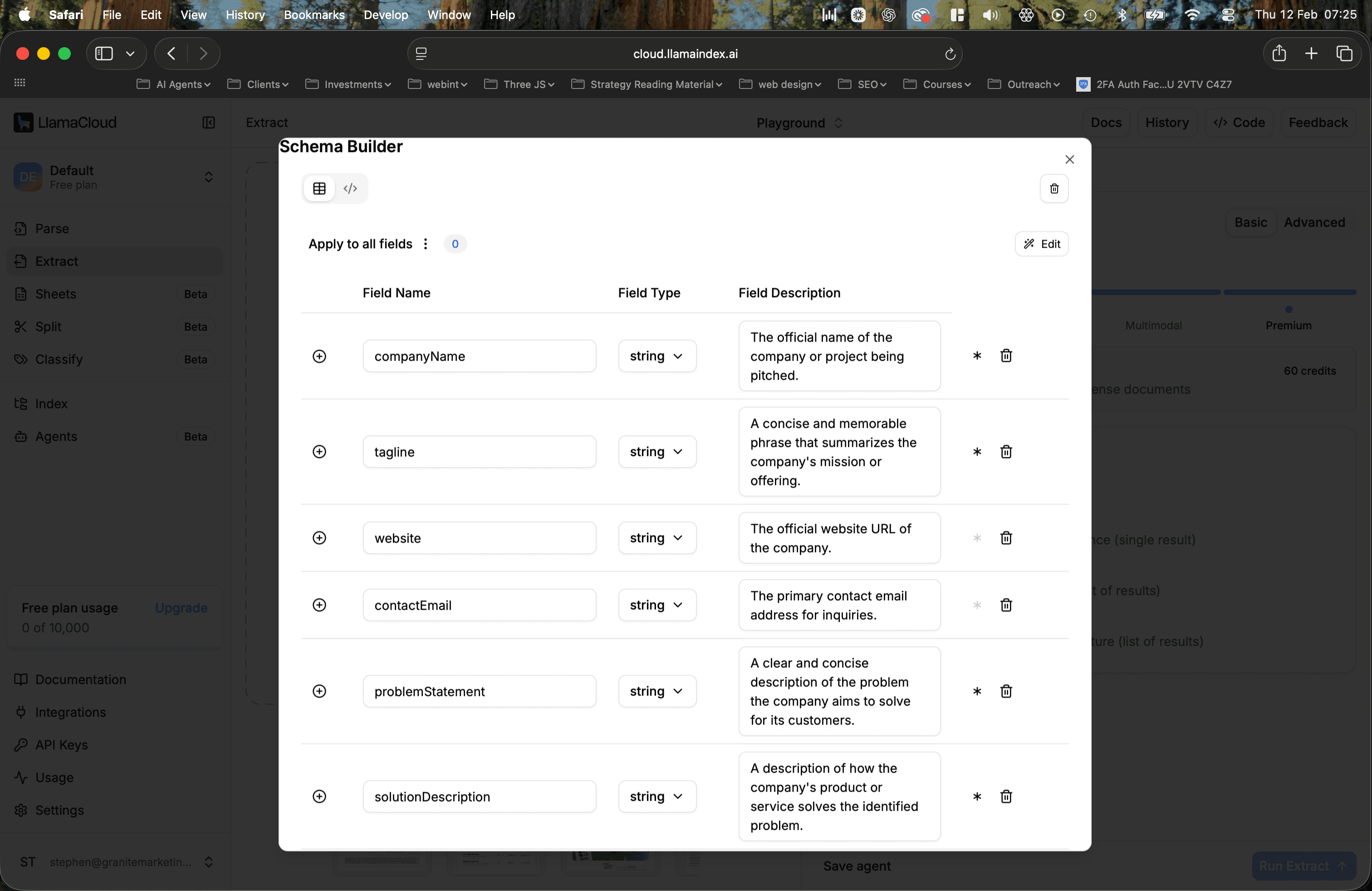
8. Click update agent and publish your configuration. It’ll actually show you any changes you’ve made as well which is very handy.
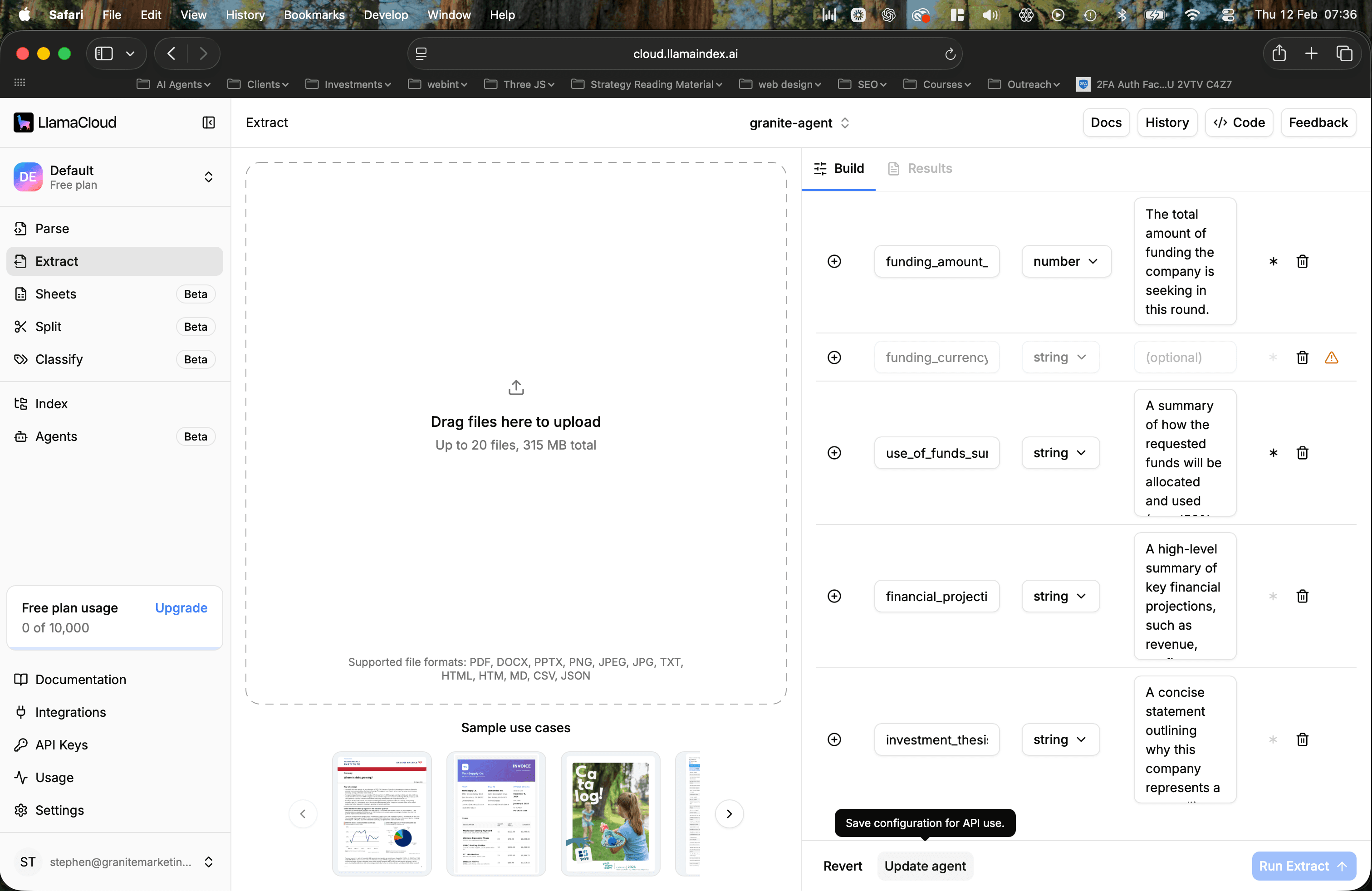
9. Keep a record of your agents name somewhere
That’s it, you’re now setup and ready to start setting up everything inside of n8n.
How the Workflow Works
Here's the high-level flow:
- Fetch the extraction agent ID by name
- Download the PDF you want to process
- Upload the PDF to LlamaIndex Cloud to create a file object
- Start an extraction job using your agent and file
- Poll the job status until it's complete
- Retrieve the structured data from the completed job
LlamaIndex runs extraction jobs asynchronously, which means you kick off the job and then check back periodically until it's done. This is perfect for n8n's loop and wait capabilities.
Let's build it step by step.
Step 1: Get Your API Key
Before we begin, it's important to know where to get your API key. Now, this is relatively straightforward in Llamaindex because once you land on the main dashboard after signing up, you'll see a page that looks like this. And all you have to do is click on the API keys in the bottom left corner.
Then you just have to create your API key, and that’s it.
Pro Tip: It's usually good practise to create an API key that serves a specific function. So some examples being a specific client or a particular section of a project. This will help you track usage to see which part of your workflows are the most labour-intensive.
Step 2: Get Your Extraction Agent ID
First, you need to tell LlamaIndex which extraction agent to use. If you know the agent's name, granite-agent in our case, you can look up its ID with a simple API call.
In n8n, add an HTTP Request node with these settings:
- Method: GET
- URL:
https://api.cloud.llamaindex.ai/api/v1/extraction/extraction-agents/by-name/YOUR_AGENT_NAME - Authentication: Generic Credential Type
- Header Auth
- Name:
Authorization - Value:
Bearer YOUR_LLAMA_CLOUD_API_KEY
Replace YOUR_AGENT_NAME with the name of your extraction agent (e.g., pitch_deck_extractor).
Tip: Don't add your API key directly to the HTTP node. You want to select an authentication type of "generic credential type", then you want to select "generic auth type" as "bearer", and then that's where you create your bearer token. This means that your API keys are encrypted and they aren't visible in the workflow, which can be useful if you want privacy, and you can add that same authentication to multiple HTTP nodes, across workflows, without having to copy and paste it every time.
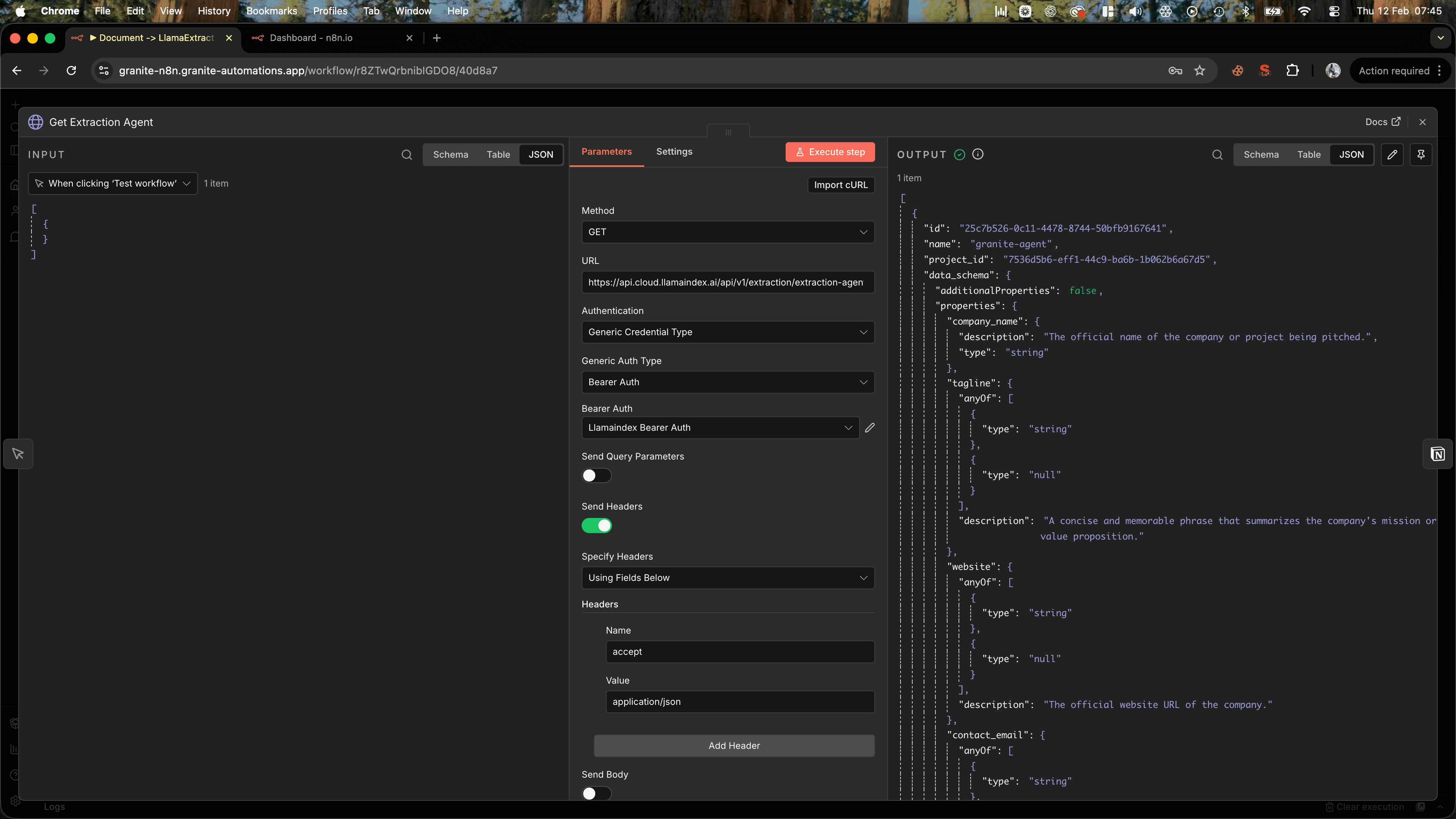
The response will include an id field. You'll use this in later steps, so make sure to reference it as {{ $json.id }} in subsequent nodes.
Why this step matters: LlamaIndex uses agent IDs internally, but it's easier for you to reference agents by name. This lookup step bridges that gap.
Step 3: Download the PDF
Next, you need to get the PDF you want to process. This could come from anywhere: a webhook, a cloud storage bucket, an email attachment, or a direct URL.
For this example, we'll assume you have a direct URL to a PDF.
Add another HTTP Request node:
- Method: GET
- URL:
https://example.com/path/to/pitch-deck.pdf - Response Format: File
Setting the response format to "File" tells n8n to treat the response as binary data, which is exactly what LlamaIndex expects.
Step 4: Upload the PDF to LlamaIndex Cloud
Before LlamaIndex can extract data, it needs a reference to your file. You create this by uploading the PDF and getting back a file_id.
Add an HTTP Request node:
- Method: POST
- URL:
https://api.cloud.llamaindex.ai/api/v1/files - Authentication: Same header auth as before
- Body Content Type: Form Data
- Body Parameters:
- Name:
upload_file - Value:
data(this references the binary data from the previous step)
- Name:
The response will include a file_id. Save this as {{ $json.id }} for the next step.
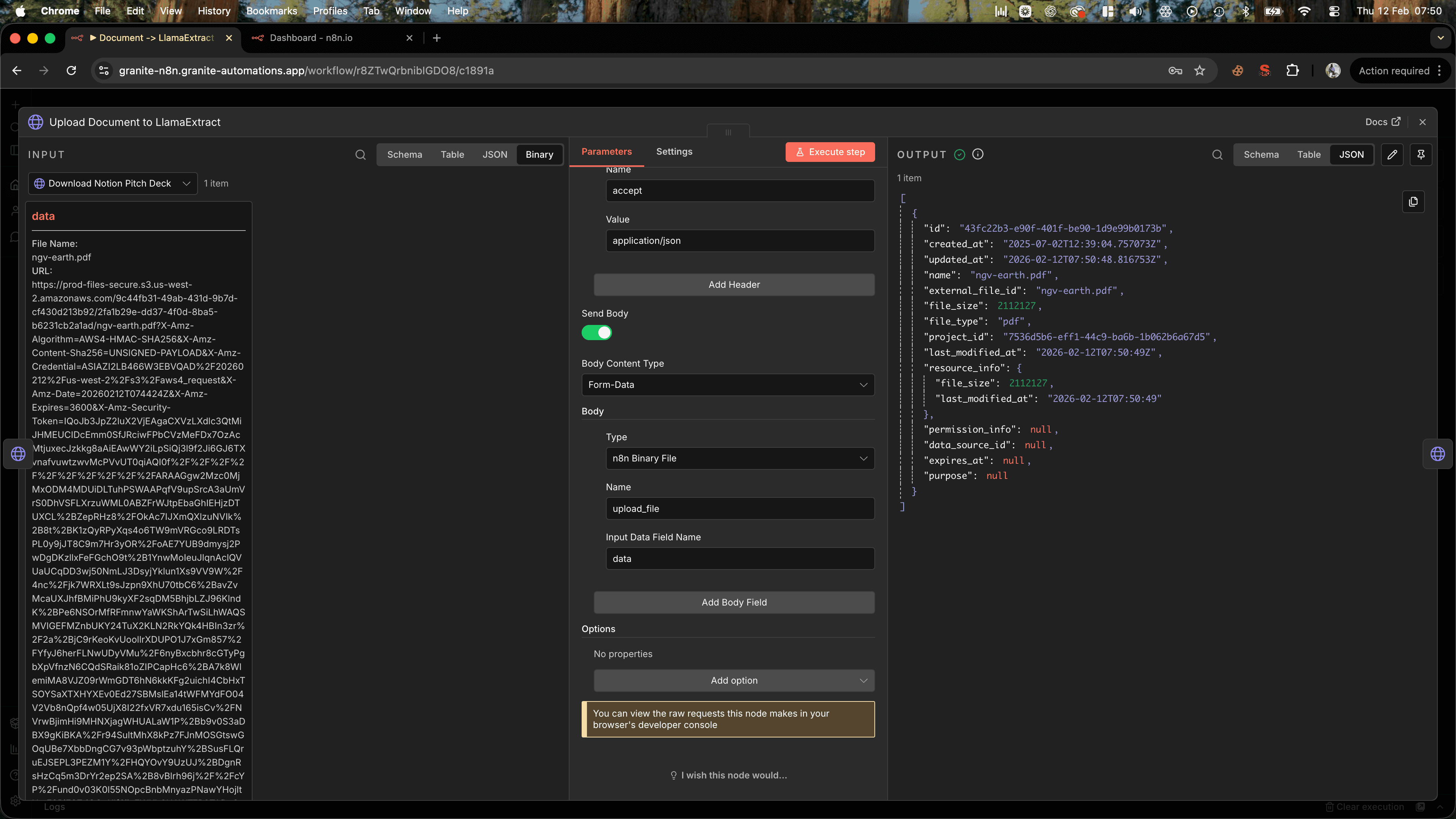
Tip: If you're processing multiple files, you can loop through them here. Just make sure each file gets its own file_id before moving forward.Step 5: Start the Extraction Job
Now you can kick off the actual extraction.
Add another HTTP Request node:
- Method: POST
- URL:
https://api.cloud.llamaindex.ai/api/v1/extraction/jobs - Authentication: Same header auth
- Body Content Type: JSON
- Body:
{
"webhook_configurations": [
{
"webhook_url": "your-webhook-url",
"webhook_headers": {},
"webhook_events": [
"extract.pending", "extract.success", "extract.error", "extract.partial_success"
]
}
],
"extraction_agent_id": "{{ $('Get Extraction Agent').item.json.id }}",
"file_id": "{{ $('Upload Document to LlamaExtract').item.json.id }}",
"data_schema_override": {},
"config_override": {
"priority": "low",
"extraction_target": "PER_DOC",
"extraction_mode": "BALANCED",
"multimodal_fast_mode": false,
"use_reasoning": false,
"cite_sources": false,
"chunk_mode": "PAGE",
"invalidate_cache": false
}
}Replace 'Get Agent ID' and 'Upload PDF' with the actual names of your nodes.
The response will include a job_id. This is what you'll use to check the status and retrieve results if you go down the polling route.
Using Llamaindex With Webhooks
You can also set a webhook URL to trigger when the analysis is completed which is a much cleaner solution. Just don't forget to set it to POST, I always do and wonder why it isn't working...
Just be aware that the webhook sends two requests:
- One to let you know that it's pending
- Another one when it is completed
Therefore, we have to set up a filter to grab the successful response. Then, we use a set node and set the body type to object, which just makes accessing the id simple to allow us to get the results of the execution.
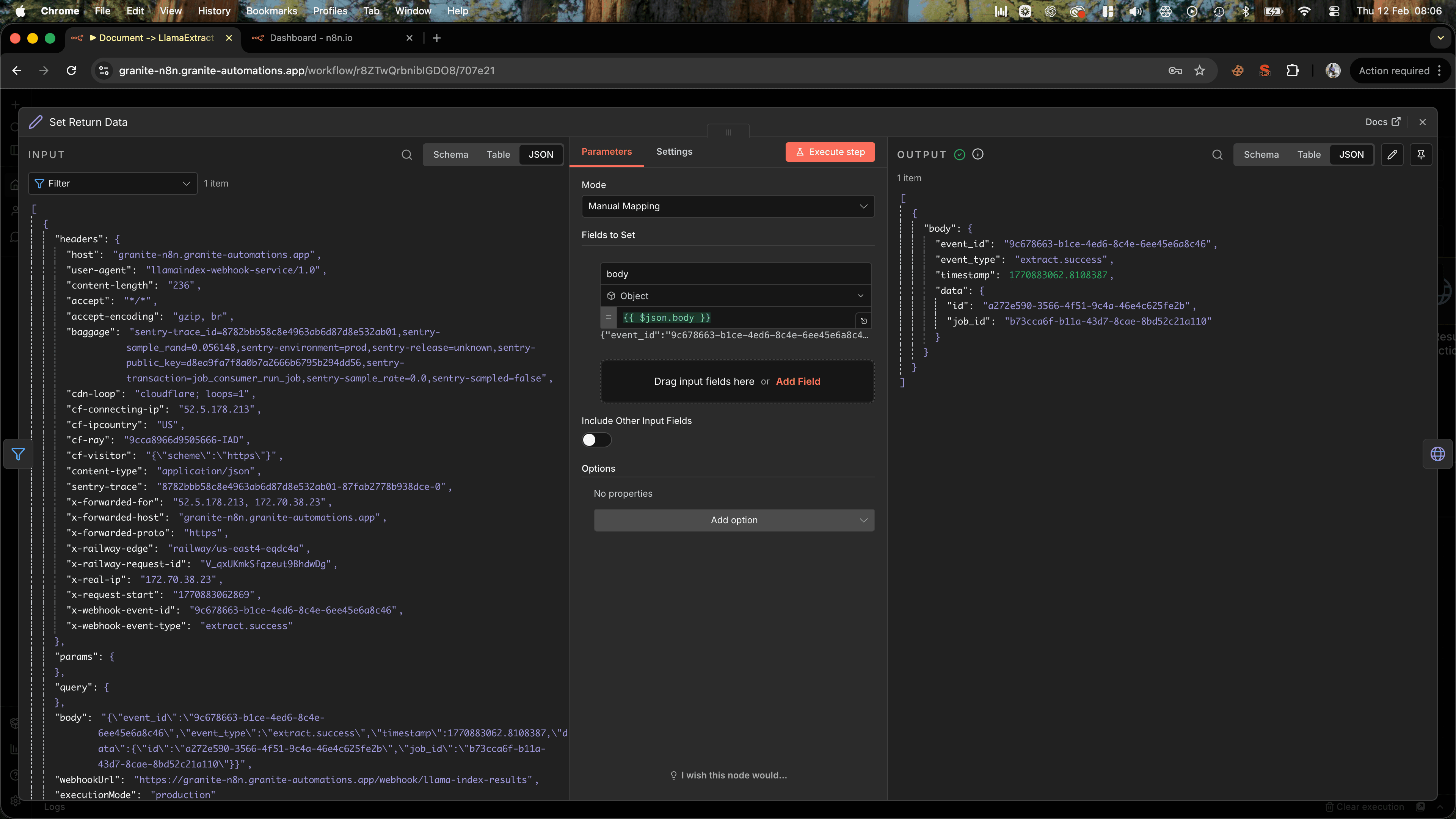
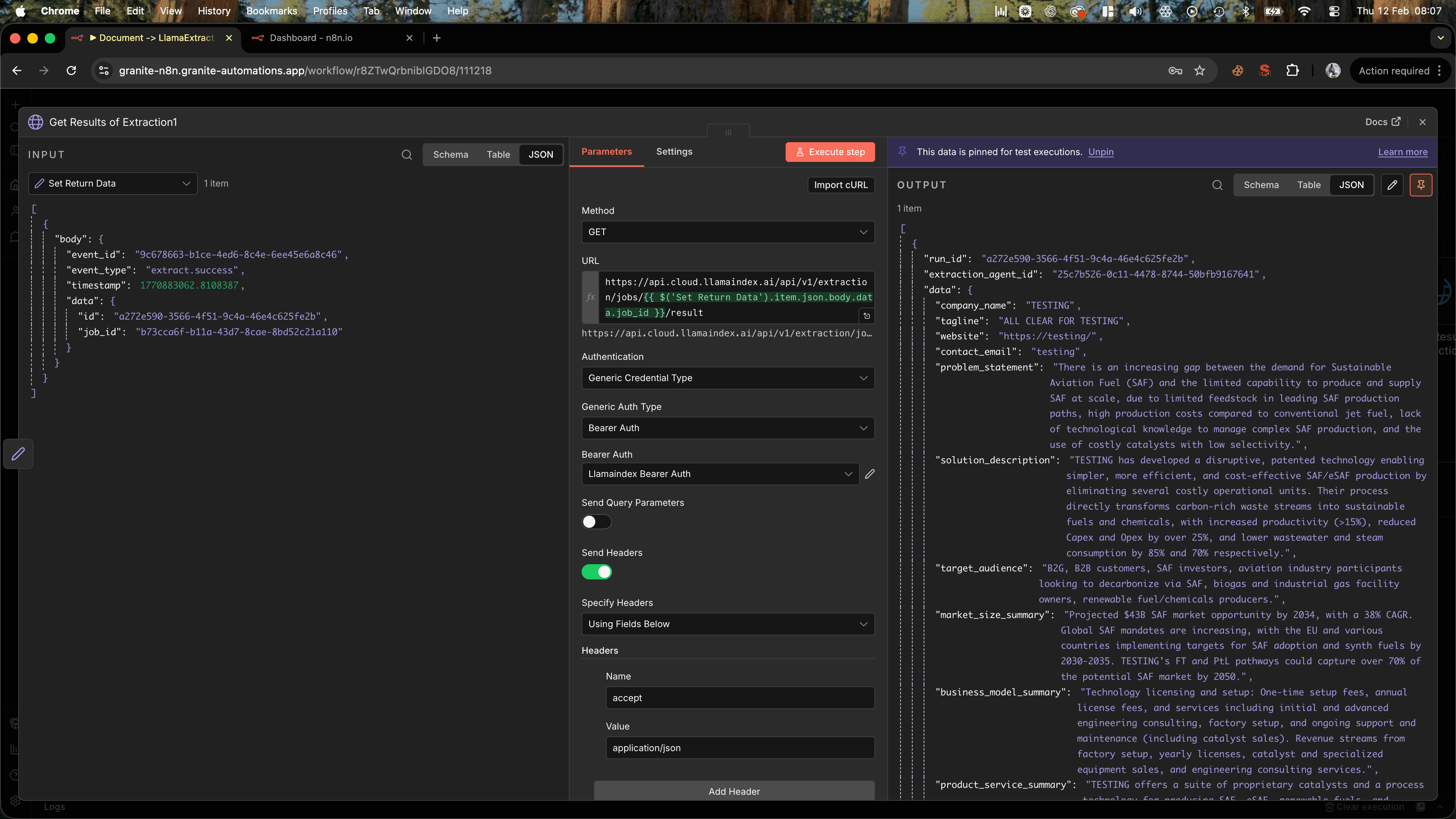
Add an HTTP Request node:
- Method: GET
- URL:
https://api.cloud.llamaindex.ai/api/v1/extraction/jobs/{{ $('Set Return Data').item.json.body.data.job_id }}/result - Authentication: Same header auth
Optional parameters:
You don’t need to touch most of these to get started. The defaults are sensible. But if you want more control, here’s what’s available:
- extraction_mode: Control how the extraction runs (default is usually fine).
- Choose between speed and accuracy — for example, FAST for quicker runs, BALANCED for most use cases, or more advanced modes for complex layouts and tables.
- system_prompt: Add custom instructions to guide the extraction (useful if you need specific formatting or context).
- This is helpful when you want stricter outputs or domain-specific behaviour.
- priority: Set job priority (e.g., "low").
- Useful if you’re running large batches and want to manage cost or queue behaviour.
- extraction_target: Decide how results are grouped.
- PER_DOC returns one structured result per document.
- PER_PAGE or PER_TABLE_ROW can split output into more granular entries.
- multimodal_fast_mode: Speed up multimodal extraction.
- Trades a bit of quality for faster processing. Usually safe to leave off unless optimising for cost.
- use_reasoning: Enable deeper reasoning during extraction.
- Helpful when information isn’t explicitly stated and needs interpretation.
- cite_sources: Return citation metadata.
- Adds page references and source locations so you can trace exactly where each value came from.
- chunk_mode: Control how the document is split before extraction.
- PAGE is standard. Other modes can help with structured or sectioned documents.
- invalidate_cache: Force a fresh extraction.
- Useful during testing if you’ve updated a document and don’t want cached results.
- data_schema_override: Temporarily override the agent’s schema.
- Great for one-off experiments without creating a new extraction agent.
- webhook_configurations: Receive real-time status updates.
- Instead of polling for results, you can trigger a webhook when the job is pending, successful, partially successful, or fails.
For the webhook, that's it. If you do want to use the polling version, then you can continue on to the following steps.
Step 6: Poll the Job Status (If Not Using Webhook)
Extraction jobs don't finish instantly: they can take anywhere from a few seconds to a couple of minutes depending on document complexity.
You need to check the job status periodically until it's complete.
Add a Loop Over Items node (or use the Wait node with a loop) to poll the status every 30 seconds.
Inside the loop, add an HTTP Request node:
- Method: GET
- URL:
https://api.cloud.llamaindex.ai/api/v1/extraction/jobs/{{ $('Start Extraction Job').item.json.id }} - Authentication: Same header auth
The response will include a status field. Possible values are:
pendingin_progresscompletedfailed
Use an IF node to check if status equals completed. If not, wait 30 seconds and check again. If yes, move to the next step.
Why polling matters: LlamaIndex processes jobs asynchronously to handle large documents efficiently. Polling is the standard pattern for working with async APIs—you're not blocking the workflow, just checking in periodically.
Step 7: Retrieve the Extracted Data (If Not Using Webhook)
Once the job is complete, you can fetch the structured data.
Add a final HTTP Request node:
- Method: GET
- URL:
https://api.cloud.llamaindex.ai/api/v1/extraction/jobs/{{ $('Start Extraction Job').item.json.id }}/result - Authentication: Same header auth
The response will be a JSON object matching the schema you defined in your extraction agent.
For a pitch deck, it might look like this:{
"company_name": "Acme AI",
"funding_amount": "$2M",
"team_size": 5,
"market_description": "AI-powered analytics for e-commerce brands",
"founders": ["Jane Doe", "John Smith"]
}
Now you can route this data wherever you need it—into a Google Sheet, a CRM, a database, or even trigger a follow-up workflow.
Understanding Extraction Schemas
The real power here is in the schema. This is where you define exactly what data you want and how it should be structured.
When you create an extraction agent in LlamaIndex Cloud, you can:
- Manually define fields: Specify field names, types (string, number, array), and descriptions
- Auto-generate from examples: Upload sample documents and describe what you want—LlamaIndex will infer the schema (what we did in this tutorial)
For a pitch deck, a good schema might include:
company_name(string)funding_amount(string)team_size(number)market_description(string)founders(array of strings)problem_statement(string)solution_overview(string)
The more specific your schema, the better the extraction quality. If you need a date formatted a certain way, or a currency amount without symbols, you can add instructions in the field description.
Pro tip: Start with a simple schema and iterate. Test with a few documents, see what gets extracted correctly, and refine from there.
What You Can Do With the Extracted Data
Once you have structured JSON, the possibilities open up:
- Auto-populate a CRM: Send company details directly into Salesforce, HubSpot, or Airtable
- Build a deal pipeline: Track funding asks, team sizes, and market focus across dozens of decks
- Generate summaries: Feed the extracted data into an AI summarisation tool to create one-pagers
- Trigger follow-ups: If funding amount exceeds a threshold, automatically send an email or Slack message
- Create dashboards: Aggregate data across documents to spot trends (e.g., average funding ask by industry)
In our test run, we extracted data from a pitch deck in under two minutes: something that would've taken 15+ minutes manually. And because it's structured, we could immediately filter, sort, and analyse it without any cleanup.
Tips and Gotchas
Handle failed jobs gracefully: Always check the status field. If a job fails, the API will return an error message: log it and alert yourself so you can investigate.
Watch your API rate limits: LlamaIndex Cloud has rate limits depending on your plan. If you're processing dozens of documents, consider batching or adding delays between jobs.
Test your schema thoroughly: The quality of extraction depends heavily on your schema. Test with a variety of documents to make sure it handles edge cases (missing fields, unusual formatting, etc.).
Use system prompts for edge cases: If the default extraction isn't quite right, you can add a system prompt to guide the model. For example: "Extract funding amount as a number without currency symbols."
Store file IDs if you need to reprocess: If you might want to re-run extraction with a different schema later, save the file_id: you won't need to re-upload the document.
Wrapping Up
LlamaIndex Extraction turns unstructured PDFs into structured, machine-readable data, and when you combine it with n8n, you can automate the entire process end-to-end.
This isn't just about saving time (though that's a big win). It's about making data accessible in a way that lets you build smarter workflows. Instead of manually copying fields into spreadsheets, you can route data directly into systems that act on it: CRMs, databases, analytics tools, AI agents.
If you're processing documents regularly: pitch decks, invoices, contracts, research papers, this approach scales in a way manual extraction never could.
The next time you're staring at a stack of PDFs, remember: you don't have to extract that data by hand. Let the machines do it.


